The world of digital content creation is evolving at an incredible pace, and influencers are often the first to adopt new technologies that help them stay ahead of the curve...
In today’s digital marketing world, businesses are constantly looking for innovative ways to reach their target audiences more effectively. Traditional advertising methods are evolving, and AI-powered solutions are rapidly taking..
In today’s digital-first marketing landscape, automation and artificial intelligence are transforming how businesses run their advertising campaigns. Google Ads has always been a powerful platform, but the manual process of..
Static images are useful, but motion is often what makes people stop scrolling. A product photo can become a short ad, an illustration can turn into a cinematic scene, and..
Most early-stage teams do not need a complete brand campaign on day one. They need enough visual material to explain the product, make the launch page feel intentional, and learn..
If you run a small business, a shop, or even a personal brand online, you already know one thing — customers today do not like filling long contact forms or..
Every gamer starts with the same challenge. Before entering multiplayer matches, joining gaming communities, or competing against players worldwide, they need a username. At first, choosing a gamer tag may..
Dreamwork: How AI Is Transforming the Modern Job Search ExperienceFinding a new job has become increasingly complex. Professionals today spend countless hours searching through job boards, customizing resumes, writing cover..
Creating a Perler bead pattern used to require hours of manual work. You had to resize your image, reduce colors, count beads, and redraw everything on graph paper.Today, AI can..
In the fast-paced world of short-form video, TikTok reigns supreme. As creators, we pour our energy into making every second count, from the perfect hook to the final CTA. But..
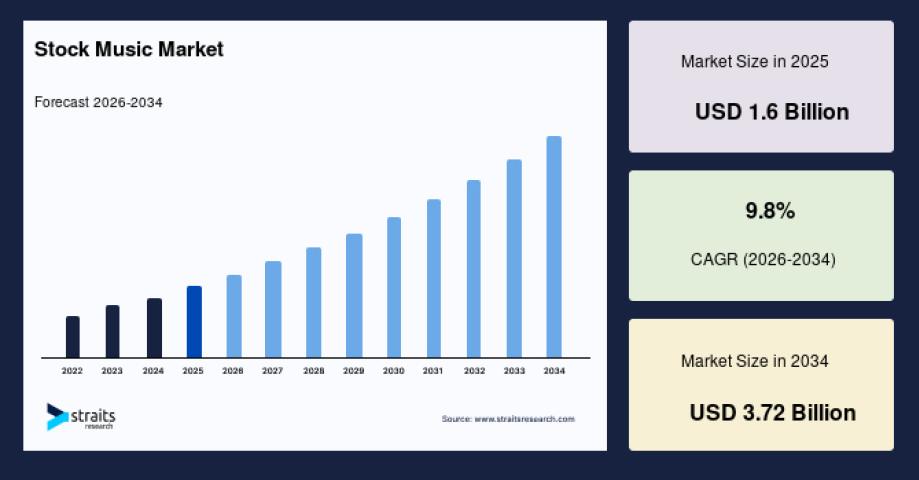
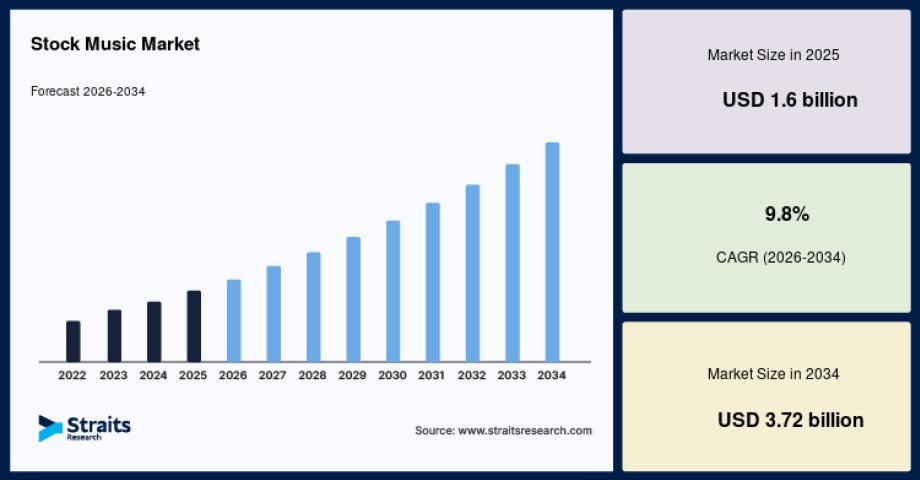
The global stock music market is experiencing significant growth due to the rapid expansion of digital content creation, increasing demand for royalty-free music, and the growing popularity of video streaming..
According to IMARC Group's report titled "India
Music Streaming Market Size, Share, Trends and Forecast by Revenue Model,
Service, Platform, and Region, 2025-2033", The report offers a
comprehensive analysis of..
The rise of digital music
distribution has redefined the way artists release and share their
work. However, while this offers significant opportunities, emerging artists
encounter a myriad of challenges. This..
In the fast-evolving music industry,
digital
music distributors have become vital players in getting music to a global
audience. Artists, whether independent or signed, rely on digital distribution
to ensure..
Music has become an essential part of everyday life. Whether you're working, exercising, traveling, or simply relaxing, having your favorite songs available offline is convenient. While streaming services dominate the..
The global powder coatings market is witnessing steady growth due to increasing demand for environmentally friendly coating solutions, rising industrialization, and expanding applications across automotive, construction, and consumer goods industries...
The tectonic shift in the landscape of generative video. In the infancy of AI video, the industry was mesmerized by the ability to simply move an image around. But as..
Creativity is becoming more accessible to everyone. The music industry is now open to everyone. With the ai music generator, you don't have to spend years learning music theory or..