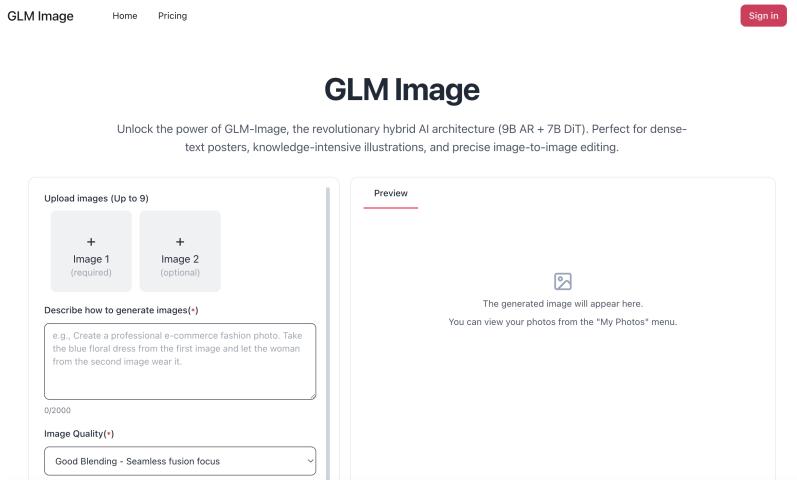
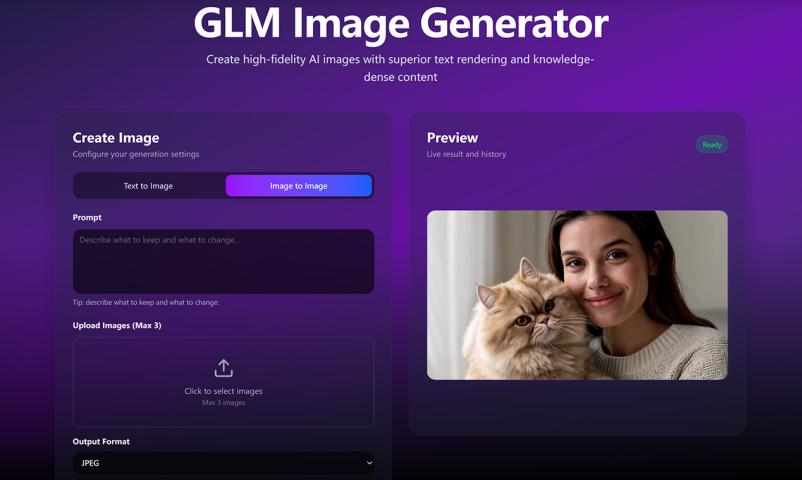
The SOTA AR+Diffusion AI for Text-to-Image & Editing
|
Founded year:
|
2026
|
|
Country:
|
United States of America
|
|
Funding rounds:
|
Not set
|
|
Total funding amount:
|
Not set
|
Description
GLM-Image is an open-source, hybrid image generation model that combines a 9B auto-regressive module with a 7B diffusion decoder to balance semantic logic with visual detail. By utilizing semantic-VQ tokens and targeted reinforcement learning, it attempts to improve performance in challenging areas like instruction following and character rendering. While aligning with current industrial standards for image quality, it primarily serves as a practical framework for exploring how auto-regressive architectures can enhance information density and text accuracy in generative tasks.